20 de mayo de 2026
La adopción de agentes de voz con IA está creciendo rápidamente en industrias como customer service, ventas, soporte técnico, salud y operaciones internas. Sin embargo, existe un factor que define el éxito o fracaso de estas implementaciones: la latencia.
Cuando un usuario habla con un agente de voz, espera una conversación fluida e inmediata. Si la IA tarda demasiado en responder, interrumpe el ritmo natural de la interacción y genera frustración, abandono o pérdida de confianza en el sistema.
En proyectos empresariales, una diferencia de apenas cientos de milisegundos puede impactar directamente la experiencia del usuario. Por eso, optimizar la baja latencia de voice AI ya no es un detalle técnico: es un requisito crítico de producto.
En este artículo exploraremos cómo reducir la latencia en agentes de voz con IA, qué factores afectan el rendimiento en tiempo real y cómo diseñar arquitecturas de voice AI capaces de funcionar correctamente en producción.
¿Qué significa latencia en agentes de voz con IA?
La latencia es el tiempo que transcurre entre la entrada del usuario y la respuesta del agente de voz.
En sistemas modernos de AI voice agents, ese proceso normalmente incluye:
- Captura de audio
- Speech-to-Text (STT)
- Procesamiento del LLM
- Orquestación del call flow
- Text-to-Speech (TTS)
- Reproducción de audio
Cada etapa introduce retrasos. Si la arquitectura no está optimizada, la experiencia se siente lenta, artificial y poco conversacional.
Los usuarios actuales esperan agentes de voz de IA en tiempo real que respondan con velocidades similares a una conversación humana. En la práctica, eso significa mantener respuestas percibidas por debajo de los 1-2 segundos.
Principales causas de latencia en Voice AI
Muchas empresas asumen que el problema está únicamente en el modelo de IA. En realidad, la latencia suele ser el resultado acumulativo de múltiples componentes.
1. Modelos demasiado grandes
No todos los flujos requieren modelos gigantes. Usar un LLM extremadamente pesado para tareas simples aumenta innecesariamente el tiempo de inferencia.
En entornos de producción, una estrategia eficiente consiste en combinar:
- modelos pequeños para intents simples
- modelos medianos para razonamiento contextual
- escalamiento selectivo para tareas complejas
Esta arquitectura reduce significativamente los tiempos de respuesta.
2. Pipelines secuenciales
Uno de los errores más comunes es ejecutar cada componente de forma lineal:
- STT termina
- luego inicia el LLM
- luego inicia TTS
Los agentes de voz modernos funcionan mejor con pipelines paralelos y streaming en tiempo real.
Por ejemplo:
- transcripción parcial mientras el usuario habla
- generación anticipada de respuesta
- streaming progresivo de voz
Esto permite disminuir la percepción de espera incluso antes de completar el procesamiento total.
3. Infraestructura distribuida incorrectamente
Muchas implementaciones fallan porque:
- el modelo está en una región
- el TTS en otra
- la base de datos en otra ubicación
Cada salto de red agrega milisegundos críticos.
Para lograr baja latencia en voice AI, la proximidad entre servicios es fundamental. Edge computing, inferencia regional y procesamiento cercano al usuario son estrategias clave.

Diseño de call flows para agentes de voz que sí funcionan en producción
La latencia no depende únicamente de infraestructura. El diseño conversacional también impacta directamente el rendimiento.
Uno de los mayores problemas en voice AI ocurre cuando los agentes deben manejar conversaciones largas, ambiguas o no lineales sin una estructura clara.
En producción, los call flows complejos suelen fallar cuando:
- existen demasiadas bifurcaciones
- no hay manejo de contexto
- el agente intenta razonar todo desde cero
- no existen mecanismos de recuperación conversacional
Un buen diseño de call flow debe priorizar:
- rutas conversacionales claras
- intents bien definidos
- memoria contextual limitada y eficiente
- validaciones tempranas
- respuestas cortas y accionables
Los agentes de voz más efectivos no son necesariamente los que “hablan más”, sino los que resuelven tareas rápidamente.
Además, dividir procesos complejos en micro-flujos ayuda a reducir procesamiento innecesario del LLM y mejora la estabilidad conversacional.
Cómo crear agentes de voz que suenan humanos (y no robots)
Otra preocupación frecuente en empresas que evalúan voice AI es la naturalidad de la conversación.
Los usuarios detectan inmediatamente cuando un sistema:
- responde demasiado lento
- usa pausas artificiales
- corta frases incorrectamente
- tiene entonación robótica
- no entiende interrupciones
La naturalidad depende tanto de la voz como de la velocidad de respuesta.
Para crear agentes de voz más humanos, recomendamos:
Uso de TTS neural en streaming
Los motores de síntesis modernos permiten generar audio progresivamente sin esperar la respuesta completa.
Esto reduce silencios incómodos y mejora la sensación de conversación natural.
Manejo de interrupciones (barge-in)
Un agente avanzado debe permitir que el usuario interrumpa la respuesta sin romper el flujo conversacional.
Este capability es esencial en agentes de voz de AI en tiempo real.
Latencia conversacional baja
Incluso la mejor voz neural pierde naturalidad si responde tarde.
En voice AI, velocidad y percepción humana están completamente conectadas.
Respuestas diseñadas para voz
Muchos equipos reutilizan textos creados para chatbots escritos. Esto suele producir conversaciones poco naturales.
El contenido optimizado para voz debe:
- usar frases más cortas
- evitar estructuras complejas
- sonar conversacional
- reducir redundancias
Arquitecturas modernas para agentes de voz en tiempo real
Las implementaciones más exitosas de voice AI suelen compartir ciertos patrones técnicos:
Arquitectura basada en streaming
Streaming bidireccional para:
- audio
- transcripción
- inferencia
- síntesis de voz
Orquestación inteligente
Separación entre:
- intent detection
- retrieval
- razonamiento
- ejecución de acciones
Caché contextual
Evitar recalcular información repetitiva durante la conversación.
Retrieval optimizado
El acceso lento a bases de datos o RAG systems puede destruir la experiencia de voz.
La recuperación contextual debe estar optimizada para consultas en tiempo real.
La experiencia del usuario depende de milisegundos
En interfaces conversacionales de voz, los usuarios son mucho menos tolerantes a los retrasos que en interfaces visuales.
Un dashboard lento puede resultar molesto.
Un agente de voz lento rompe completamente la conversación.
Por eso, optimizar agentes de voz con IA requiere combinar:
- arquitectura escalable
- inferencia rápida
- diseño conversacional eficiente
- procesamiento en streaming
- modelos optimizados
- infraestructura distribuida correctamente
Las empresas que entienden esto logran experiencias mucho más naturales, fluidas y efectivas.
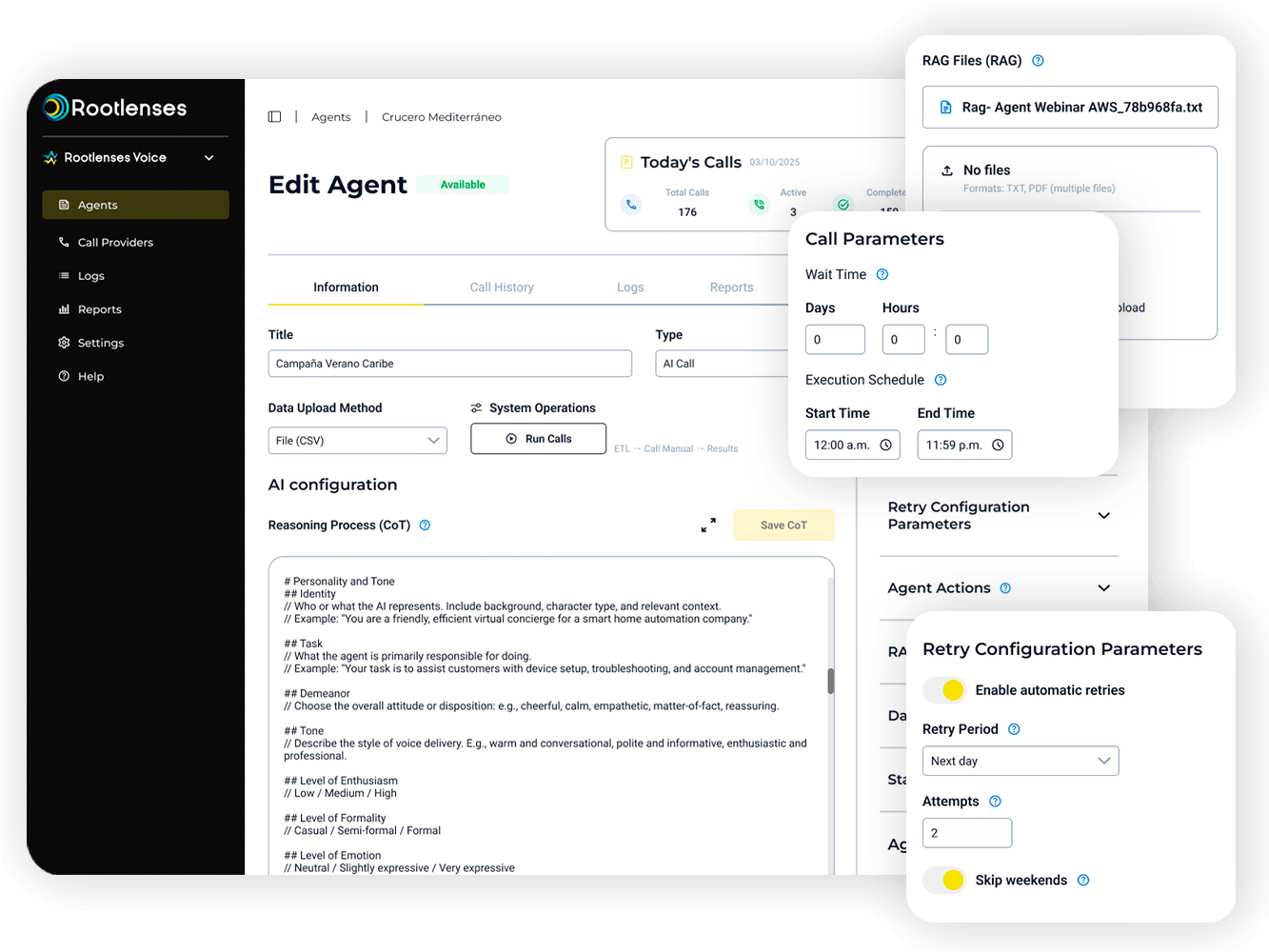
Rootlenses Voice: agentes de voz empresariales optimizados para tiempo real
Con Rootlenses Voice ayudamos a organizaciones a construir:
- agentes de voz con IA en tiempo real
- call flows robustos para conversaciones complejas
- experiencias de voz naturales y humanas
- integraciones empresariales escalables
- arquitecturas optimizadas para baja latencia
Nuestro enfoque combina ingeniería de IA, arquitectura cloud y diseño conversacional para crear agentes capaces de operar de forma estable incluso en escenarios de alta demanda.
Si tu organización está evaluando implementar voice AI empresarial, automatización conversacional o asistentes de voz inteligentes, este es el momento ideal para construir una experiencia realmente rápida y usable.


